Python Packages for Data Science
This blog is created to record the Python packages of data science found in daily practice or reading, covering the whole process of machine learning from visualization and pre-processing to model training and deployment.
This post is kept updating.
Visualization
- The quickest and easiest way to plot machine learning result, built upon scikit-learn and matplotlib
- Metrics Module – evaluation metrics, e.g. confusion matrix, ROC, etc.
- Estimators Module – learning curve and features importance
- Clusterer Module – elbow plot
- Decomposition Module – PCA 2D projection and PCA component explained variances
- Declarative statistical visualization, just like JMP but in Python
- Example:
# only need to define x, y and legend alt.Chart(cars).mark_circle().encode(x='Horsepower', y='Miles_per_Gallon', color='Origin')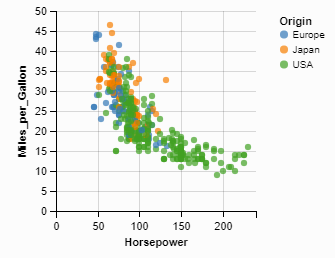
- alive data visualization dashboard
- Deep learning visualization tool supporting PaddlePaddle, PyTorch and MXNet, while Tensorflow is using Tenserboard
- Graph / scalar / image / histogram
Data Cleansing
- Work with Pandas DataFrame
- Automatically complete the basic cleansing as below
- Optionally drops any row with a missing value
- Replaces missing values with the mode (for categorical variables) or median (for continuous variables) on a column-by-column basis
- Encodes non-numerical variables (e.g., categorical variables with strings) with numerical equivalents
Feature Selection
- A visualization tool for descriptive statistical information of features, and relationship between any pair of features
- To help you fast understanding the features and make decision for feature selection and engineering
- Using genetic algorithm (explanation on KD)
Feature Engineering
- Perform automated feature engineering with Deep Feature Synthesis (DFS)
Auto Machine Learning
Leading research group on autoML Machine Learning for Automated Algorithm Design
- Genetic Algorithm / Evolutionary Computation Framework
- Using Genetic Algorithm for Optimizing Recurrent Neural Networks
- Notebooks on how to use Distributed Evolutionary Algorithm in Python
-
Search for the best pipeline of machine learning by genetic programming
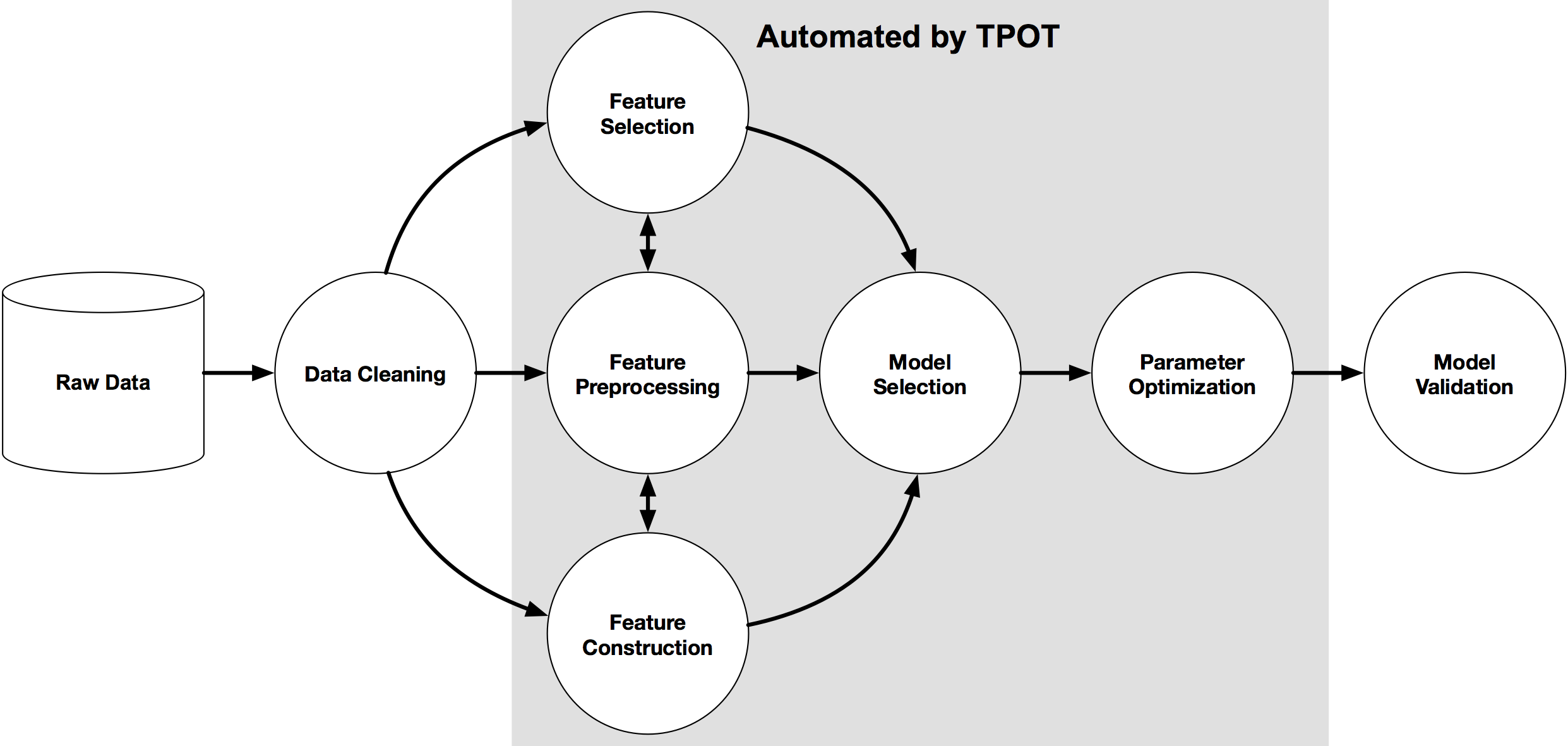
- Currently Linux only
- Tutorial on Automated Machine Learning using MLBox
- Linux only
- An automated machine learning toolkit and a drop-in replacement for a specific scikit-learn estimator
- Supporting classifers / regressors / preprocessers
import autosklearn.classification cls = autosklearn.classification.AutoSklearnClassifier() ## search the best one among all classifier cls.fit(X_train, y_train) predictions = cls.predict(X_test)
Hyperparameter Searching
- Hyperparameter search with Random Search and Tree of Parzen Estimators (TPE)
- Hyperparameter Tuning with hyperopt in Python
- Hyperopt-based model selection among machine learning algorithms in scikit-learn, without passing search space
- Support classifiers and regressors
Stacking Architecture
- Ensemble stacking for classifier or regressor, including standard version and CV version
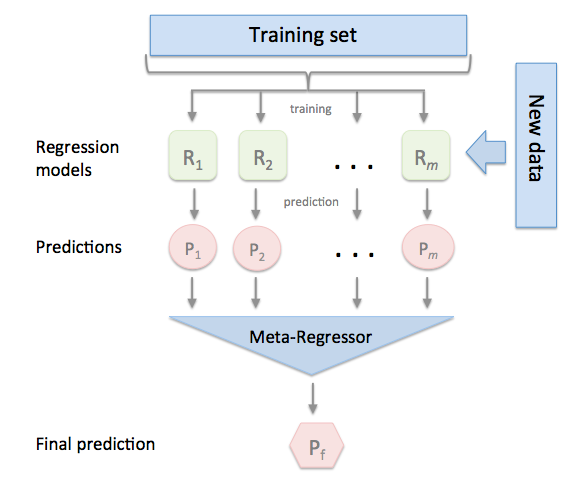
- Also has other useful tool for data science, such as feature selector
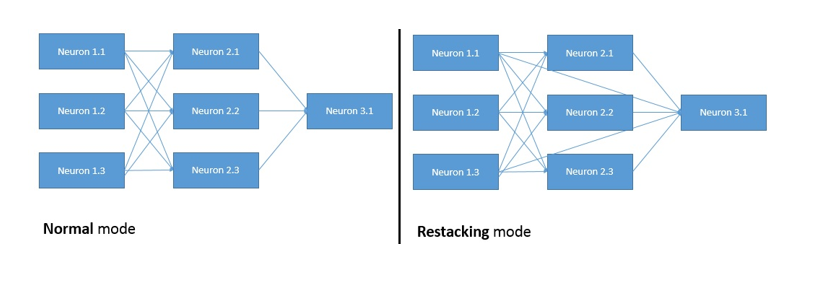
- Stacking in neural network way: replace the neurons of neural network (linear regression) with any supervised learning algorithm, and trained only from forward prop due to no gradient
- Restacking
Probabilistic Machine Learning
- Bayesian statistical modeling and Probabilistic Machine Learning which focuses on advanced Markov chain Monte Carlo and variational fitting algorithms.
- GitHub Readme includes tutorial for learning Bayesian statistics using PyMC3
Specific Data Types
Image
- Pre-trained object detection with object masking, instead of object bounding
- Art style transfer algorithm by NVIDIA
Time Series Data
Working with Time Series Data in Python
- List of Python packages about time series data
Nature Language Processing
- Industrial-Strength Natural Language Processing
- Natural Language Processing Made Easy – using SpaCy (in Python)
- Tensorflow implementation of Speech-to-Text synthesis from Baidu
- For common NLP tasks
- Natural Language Processing for Beginners: Using TextBlob
Audio Data
- Audio engineering, such as synthesizing audio training dataset by combining background noise and target sound
- Found in Deep Learning Specialization Course 5 Week 3 assignment
- Computational Jazz Improvisation
- Found in Deep Learning Specialization Course 5 Week 1 assignment
Spatial Data
Deployment
Binder 2.0
- Interactive online Jupyter notebook
- Introducing Binder 2.0 — share your interactive research environment
- Binder 2.0, a Tech Guide
Mobile Machine Learning
- A Simplified Machine Learning Library for iOS
- How to build your first Machine Learning model on iPhone (Intro to Apple’s CoreML)
Others
- Fast create model with good OOP designed code
-
Jupyter Notebook with Matlab like interface
- progression monitor 76%|████████████████████████████ | 7568/10000 [00:33<00:10, 229.00it/s]
- Portable environment for your code
- How Docker Can Help You Become A More Effective Data Scientist
- Make your Python arrange nicer and more professional
Commercial Tools
- GUI interface for data science, no coding required
- Building your first machine learning model using KNIME (no coding required!)
- GUI interface for data science, like Klarity ACE